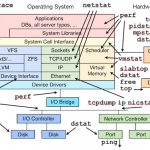
在UNIX/Linux系统中,每个打开的文件都有系统赋予的一个文件描述字,这是个小整数。一个文件被打开后,用户可以直接用这个描述字来引用对应的文件。系统为每个进程自动打开三个标准文件(即标准输入、标准输出和标准错误输出),其文件描述字分别为0,1和2。
shell上:
0表示标准输入
1表示标准输出
2表示标准错误输出
> 默认为标准输出重定向,与 1> 相同
2>&1 意思是把 标准错误输出 重定向到 标准输出.
&>file 意思是把 标准输出 和 标准错误输出 都重定向到文件file中
用例子说话:
1. grep da * 1>&2
2. rm -f $(find / -name core) &> /dev/null
上面两例中的 & 如何理解,&不是放到后台执行吗?
牛解:
1.&>file或n>&m均是一个独立的重定向符号,不要分开来理解。
2.明确文件和文件描述符的区别。
3.&>file表示重定向标准输出和错误到文件
例如:
rm -f $(find / -name core) &> /dev/null,/dev/null是一个文件,这个文件比较特殊,所有传给它的东西它都丢弃掉。
4.n>&m表示使文件描述符n成为输出文件描述符m的副本。这样做的好处是,有的时候你查找文件的时候很容易产生无用的信息,
如:2>
/dev/null的作用就是不显示标准错误输出;另外当你运行某些命令的时候,出错信息也许很重要,便于你检查是哪出了毛病,
如:2>&1
例如:
注意,为了方便理解,必须设置一个环境使得执行grep da *命令会有正常输出和错误输出,然后分别使用下面的命令生成三个文件:
grep da * > greplog1
grep da * > greplog2 1>&2
grep da * > greplog3 2>&1 //grep da * 2> greplog4 1>&2 结果一样
#查看greplog1会发现里面只有正常输出内容
#查看greplog2会发现里面什么都没有
#查看greplog3会发现里面既有正常输出内容又有错误输出内容